3 de junio de 2020
Después de casi tres meses de estar en un ERTE hoy vuelvo al trabajo.
Me he encontrado con algunos problemas menores que estoy resolviendo antes de ponerme a trazar planes a corto y medio plazo.
Asuntos resueltos
Sarajevo y la IP errónea
La máquina sarajevo.venexma.net no obtenía la IP que le correspondería según el servidor DNS interno. El problema estaba en que el servidor dhcp tenía mal la configuración.
host sarajevo {
hardware ethernet 74:d4:35:ab:f6:a4;
fixed-address 192.168.100.40;
}Thunderbird y la cuenta de Venexma en Google
Pues sí, a la vuelta se confirmó el cambio de autorización para acceder a las cuentas de Gmail (con el dominio de la empresa) y la única diferencia es que hay que activar el tipo de autentificación OAuth2.
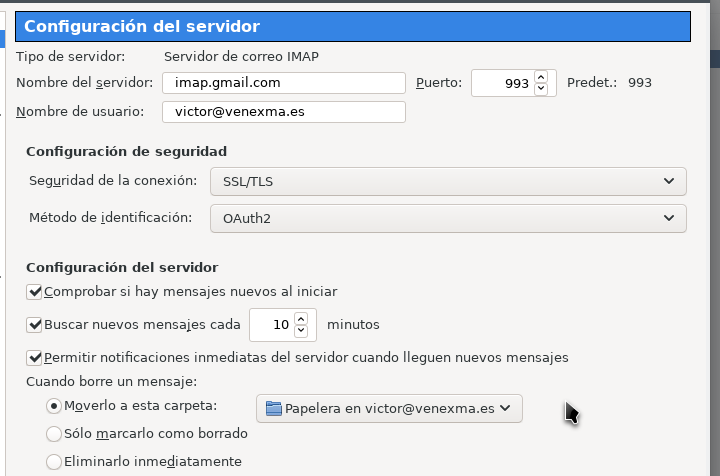
mail en Thunderbird
Acceso a cuenta de correo interna vía Dovecot
Pues también he tenido problemas aunque creo que esto es un asunto ya viejo. Por otra parte las conexiones seguras tampoco funcionaban.
He añadido lo siguiente a su configuración:
passdb {
driver = ldap
args = /etc/dovecot/dovecot-ldap.conf.ext
}
userdb {
driver = ldap
args = /etc/dovecot/dovecot-ldap.conf.ext
}
ssl_dh = </etc/dovecot/dh.pemPara recrear los parámetros DH de las conexiones seguras he debido emplear lo siguiente:
$ sudo openssl dhparam 4096 > /etc/dovecot/dh.pem
$ sudo chmod 0400 /etc/dovecot/dh.pemY en el archivo indicado la definición para usar el directorio LDAP y obtener los usuarios es:
uris = ldapi:///
auth_bind = yes
auth_bind_userdn = uid=%u,ou=users,dc=venexma,dc=net
pass_attrs = uid=user
pass_filter = (&(objectClass=posixAccount)(uid=%u))Y mira tú por dónde resulta que en el buzón de entrada tengo cerca de 148.000 mensajes esperando revisión. Vamos, van dados.
Borrado total para partir de cero.
consolas.venexma.net no está funcionando
Las máquinas virtuales en sigfrido.venexma.net no arrancan
Limpieza de paquetes innecesarios
Entre que sí y que no he procedido a eliminar varios paquetes a los que no he prestado la suficiente atención y como resultado son inútiles y sólo producen ruido en el correo.
- munin y munin-node
- nagios
Problemas serios en un disco en backups.venexma.net
Por lo visto es algo que está fallando desde hace ya un tiempo pero como he decidido eliminar de un plumazo cualquier mensaje de correo anterior al 1 de junio sólo me han quedado un par de avisos del programa mdadm.
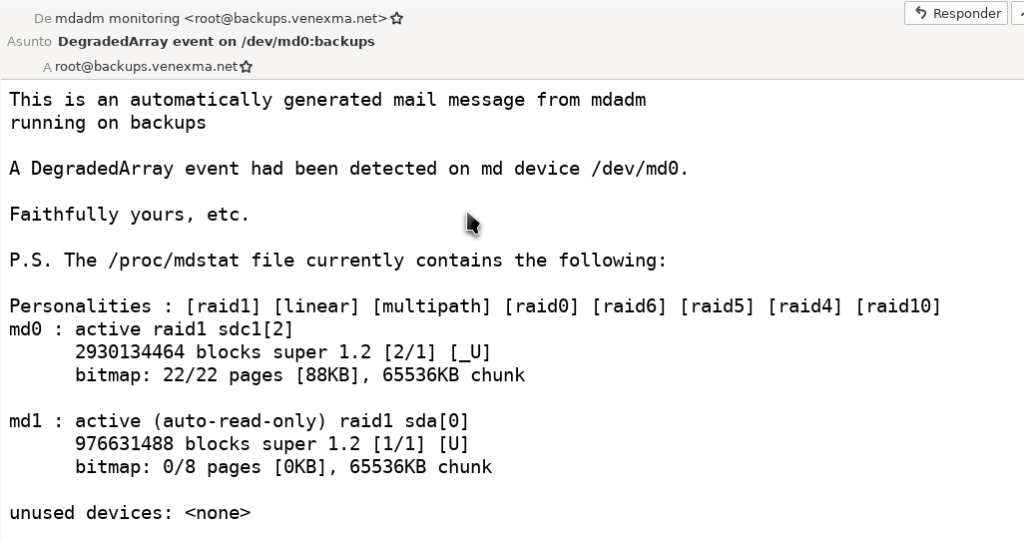
Echando un vistazo más de cerca veo que el dispositivo afectado parece ser /dev/md0 que corresponde a /dev/sdc1. Escarbando un poco más veo lo siguiente:
root@backups:/home/osr# hdparm -i /dev/sdc
/dev/sdc:
Model=WDC WD3003FZEX-00Z4SA0, FwRev=01.01A01, SerialNo=WD-WMC130D380P0
Config={ HardSect NotMFM HdSw>15uSec SpinMotCtl Fixed DTR>5Mbs FmtGapReq }
RawCHS=16383/16/63, TrkSize=0, SectSize=0, ECCbytes=0
BuffType=unknown, BuffSize=unknown, MaxMultSect=16, MultSect=16
CurCHS=16383/16/63, CurSects=16514064, LBA=yes, LBAsects=5860533168
IORDY=on/off, tPIO={min:120,w/IORDY:120}, tDMA={min:120,rec:120}
PIO modes: pio0 pio3 pio4
DMA modes: mdma0 mdma1 mdma2
UDMA modes: udma0 udma1 udma2 udma3 udma4 udma5 *udma6
AdvancedPM=no WriteCache=enabled
Drive conforms to: Unspecified: ATA/ATAPI-1,2,3,4,5,6,7
* signifies the current active modeMás preocupante es mirar la disposición de discos:
root@backups:/home/osr# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 931,5G 0 disk
└─md1 9:1 0 931,4G 0 raid1
sdb 8:16 0 3,9G 0 disk
sdc 8:32 0 2,7T 0 disk
└─sdc1 8:33 0 2,7T 0 part
└─md0 9:0 0 2,7T 0 raid1 /srv
sdd 8:48 0 232,9G 0 disk
├─sdd1 8:49 0 46,6G 0 part /
├─sdd2 8:50 0 1K 0 part
├─sdd5 8:53 0 3,7G 0 part [SWAP]
└─sdd6 8:54 0 182,6G 0 part /home
sde 8:64 0 931,5G 0 disk
└─sde1 8:65 0 931,5G 0 part /extra
Pues un disco de 3Tb en un RAID funcionando en modo degradado y que se emplea para copias de seguridad. Lo pongo como asunto urgente a resolver para mañana.
Asuntos administrativos
He puesto al día el buzón de correo principal, archivando aquellos mensajes que tuviesen que ver con la actividad de la empresa y he contestado en grupo a una docena de comerciales de distintos productos informáticos con los que estaba en contacto antes del estado de alarma.
Problemas pendientes
- El servicio de acceso a máquinas consolas.venexma.net no está funcionando: 503 Service Unavailable
- Las máquinas virtuales en sigfrido.venexma.net no terminan de arrancar. Algo le pasa al servicio libvirtd.service que no consigo que se ponga en marcha.
- Hay que recuperar el servicio de gestión de proyectos, bien a través de un tablero Kanban o de cualquier otra herramienta similar que me permita llevar la cuenta de los problemas.
root@sigfrido:/etc# systemctl status libvirtd.service
● libvirtd.service - Virtualization daemon
Loaded: loaded (/lib/systemd/system/libvirtd.service; enabled; vendor preset: enabled)
Active: failed (Result: exit-code) since Wed 2020-06-03 11:33:45 CEST; 12s ago
Docs: man:libvirtd(8)
https://libvirt.org
Process: 12606 ExecStart=/usr/sbin/libvirtd $libvirtd_opts (code=exited, status=1/FAILURE)
Main PID: 12606 (code=exited, status=1/FAILURE)
Tasks: 18 (limit: 32768)
Memory: 856.2M
CGroup: /system.slice/libvirtd.service
└─8670 /usr/sbin/libvirtd -d -l
jun 03 11:33:45 sigfrido systemd[1]: libvirtd.service: Failed with result 'exit-code'.
jun 03 11:33:45 sigfrido systemd[1]: Failed to start Virtualization daemon.
jun 03 11:33:45 sigfrido systemd[1]: libvirtd.service: Service RestartSec=100ms expired, scheduling restart.
jun 03 11:33:45 sigfrido systemd[1]: libvirtd.service: Scheduled restart job, restart counter is at 5.
jun 03 11:33:45 sigfrido systemd[1]: Stopped Virtualization daemon.
jun 03 11:33:45 sigfrido systemd[1]: libvirtd.service: Start request repeated too quickly.
jun 03 11:33:45 sigfrido systemd[1]: libvirtd.service: Failed with result 'exit-code'.
jun 03 11:33:45 sigfrido systemd[1]: Failed to start Virtualization daemon.
Pingback:Envío de correos desde odoo vía Gmail – Mi lugar de trabajo