
… empleando Apache, algunos módulos y, más tarde, mucho trabajo en la trastienda.
El problema
Pues resulta que con esto de las nuevas tecnologías algunos clientes quieren recibir copias de sus documentos, los que se crean automágicamente para ellos en el día a día, en su buzón electrónico. Y a priori no parece complicado ¿ verdad ? Hasta que unos poquitos empiezan a ser decenas, cada uno con su simpática causística (lo de perder mensajes empieza a ser de chiste), y terminas destinando a un humano a realizar una tarea aburrida, temible y propensa a errores. Y digo temible porque la peor pesadilla de la gente de ventas parece ser que un cliente reciba la factura o la lista de precios de otro. Y eso, con un operador homínido a cargo, está garantizado.
El caso es que llevamos ya un tiempo viendo la posibilidad de incorporarlo en la página web de la empresa, en un área de clientes, pero nos está costando arrancar porque sabemos poco lo que queremos y cómo lo queremos. Eso lleva tiempo y conversaciones inacabables con la empresa que está construyendo y manteniendo la página en Drupal, además de con los propios homínidos de mi empresa, que no terminan nunca de aclararse sobre qué sería bueno tener en dicha área, y yo enmedio, intentando que los costes sean razonables y que no creen bases de datos en un servidor externo a la empresa entre otras lindezas.
Y hoy precisamente he tenido una conversación con mi único power user y nos hemos dado cuenta de que lo que funciona de maravilla es la página de catálogos en PDF. Nadie tiene una queja mayor que recordar su dirección en la red, que no es poco (y es que nos hemos pasado de listos y la hemos situado en http://empresa.es/pdf y, obviamente, tiende a ser confusa. ¿ Qué puede haber allí ?).
El catálogo en PDF es un índice pelado de carpetas y documentos con un título descriptivo por idioma. Claro, servir archivos estáticos es tan simple como rápido y al final todos entiende a dónde quieren llegar y, lo mejor en mi opinión, ven de un vistazo, sin conjuntos de resultados de búsqueda fraccionados, qué hay y cuándo se ha actualizado.
 No se me ha ocurrido de momento añadir un feed RSS porque creo que no iba a usarlo ni el tato pero lo mismo un día tonto de estos me animo.
No se me ha ocurrido de momento añadir un feed RSS porque creo que no iba a usarlo ni el tato pero lo mismo un día tonto de estos me animo.
Por cierto que los documentos que los clientes reclaman -aunque aún no lo sepan- son las facturas, los albaranes, las listas de precios y las estadísticas de consumo. Todo eso se puede generar fácilmente gracias a los esfuerzos que he realizado estas últimas semanas refactorizando y reconstruyendo el sistema de generación de listados de aplicaciones de un par de décadas de edad. Da lo mismo porque como bien dice mi madre (¡ hola, mamá !): ni agradecido ni pagado.
Problemas técnicos
Partiendo de la base de que los únicos programas que quiero construir son aquellos que crean la información desde nuestra venerable (más bien vetusta) base de datos, he creado un esquema de lo que podría hacerse a nivel de sistemas para que funcionase sin cambios traumáticos.
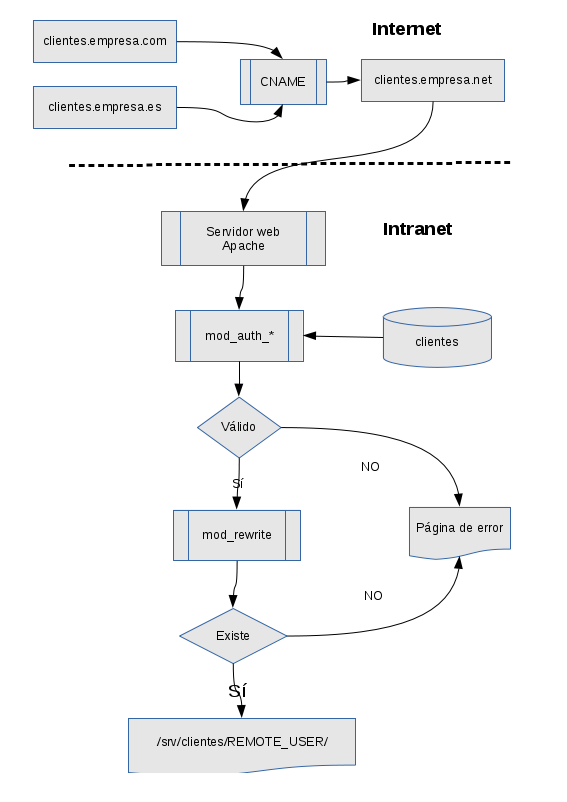
Lo que más o menos pretendo es tener un servidor virtual -inicialmente en la intranet- que solicite una identificación directa y que, tras validarle correctamente, envíe al cliente a una página simple donde pueda encontrar sus documentos, en el idioma correspondiente, y descargarlos sin más que elegirlos.
Posiblemente sea necesaria una página principal donde aterrice y se le informe de dónde o a quién puede dirigirse para pedir unas credenciales. Tal vez, más adelante, incluso se pueda dar de alta en algún tipo de formulario pero eso sería llevar las cosas más lejos de lo que ahora estoy dispuesto.
Así pues el reto consiste en:
- Identificar al cliente empleando una base de datos.
- Redirigir al cliente a su página.
- Mostrarle textos en su idioma.
- Asegurarnos de que no es posible saltar desde allí a otra página de cliente alterando un poco la dirección.
He estado recopilando información y por lo que veo se encuentran soluciones a lo anterior en:
- Las bases de datos tipo dbm son bastante sencillas de mantener desde fuera (como con Perl) y el módulo mod_authn_dbm las integra bien en Apache.
- Esto parece ser algo más complicado porque según dónde se sitúen las directivas de reescritura se dispone de los datos identificativos de una u otra forma. Brian Bennett lo explica muy bien en este artículo; ahora sólo me resta probarlo en el servidor de desarrollo.
- Emplear mod_negotiation y páginas html según idioma. Parece sencillo y más o menos estandarizado en tanto en cuanto tenga el navegador correctamente configurado. Tal vez sea necesario -en versiones posteriores- construir enlaces internos a los otros idiomas.
- Situar archivos .htaccess en los que se limite el acceso al directorio al usuario correspondiente. Los programas internos que construyen estos directorios pueden perfectamente añadir estos archivos personalizados así que tampoco es algo imposible.
Así que ahora sólo tengo que probar que todos los mecanismos funcionan correctamente antes de ponerme en serio a escribir tanto el paquete Debian que montaría el servidor virtual, como los programas de extracción de datos y construcción de páginas. En ambos lados de la línea, eso sí, pero estoy seguro de que puede merecer la pena.