
… para que pueda ser mejor transportado y más útil.
Desde hace un tiempo estoy guardando cualquier documento en papel en digital por aquello de tenerlo más a mano a la hora de enviar o compartir. De hecho es ahora cuando más uso le estoy dando al escáner casero que tengo desde hace años, un Epson Perfection 2400 PHOTO (GT-9300UF), que sigue funcionando de maravilla.
Basta con limpiarlo regularmente y emplear un programa más sencillo que xsane como Simple Scan. Este último te crea siempre un PDF con las páginas insertas como imágenes con un simple click; una a una, es verdad, pero cuando le coges el truco sorprende lo cómodo y rápido que puede ser.
Pues bien, el caso es que es tan simple de usar que hay poco que cambiar en las opciones de escaneado y los documentos suelen ser bastante monstruosos. Por una parte cada hoja puede llegar a ocupar casi tres mega bytes de tamaño y por otra, al ser sólo imágenes, se pierde la parte textual que tan útil es para realizar búsquedas o extraer textos.
Reducir el tamaño
Para reducir su tamaño podemos recurrir a la herramienta gs del paquete Ghostscript, antigua y fiable, que con algo como lo siguiente te deja el documento liviano y legible.
$gs -sDEVICE=pdfwrite -dCompatibilityLevel=1.4 -dPDFSETTINGS=/ebook -dNOPAUSE -dQUIET -dBATCH -sOutputFile=out.pdf in.pdf
El programa gs tiene varias opciones en la conversión a PDF (opción -dPDFSETTINGS que escribo aquí para futuras referencias:
- /screen: calidad de imágenes para pantallas (72 dpi)
- /ebook: baja calidad (150 dpi)
- /printer: calidad alta (300 dpi)
- /prepress: calidad alta preservando el color (300 dpi)
- /default: casi idéntica a /screen
Añadir textos
Al estar el documento formado sólo por imágenes no es posible encontrar o copiar textos sin realizar lo que se llama un reconocimiento óptico de caracteres, operación compleja dependiendo de muchos factores, pero que puede realizarse con herramientas disponibles en Linux.
Es conveniente tener en cuenta que cuanto más reduzcamos la calidad de las imágenes peor va a ser el reconocimiento.
Concretamente el programa tesseract y un frontal llamado ocrmypdf que facilita la inserción del texto reconocido en el propio documento. No es el mejor de los arreglos pero cumple muy bien su función.
Usando el programa que menciono una conversión puede realizarse como:
$ ocrmypdf --output-type pdfa --language spa --force-ocr entrada.pdf salida2.pdf
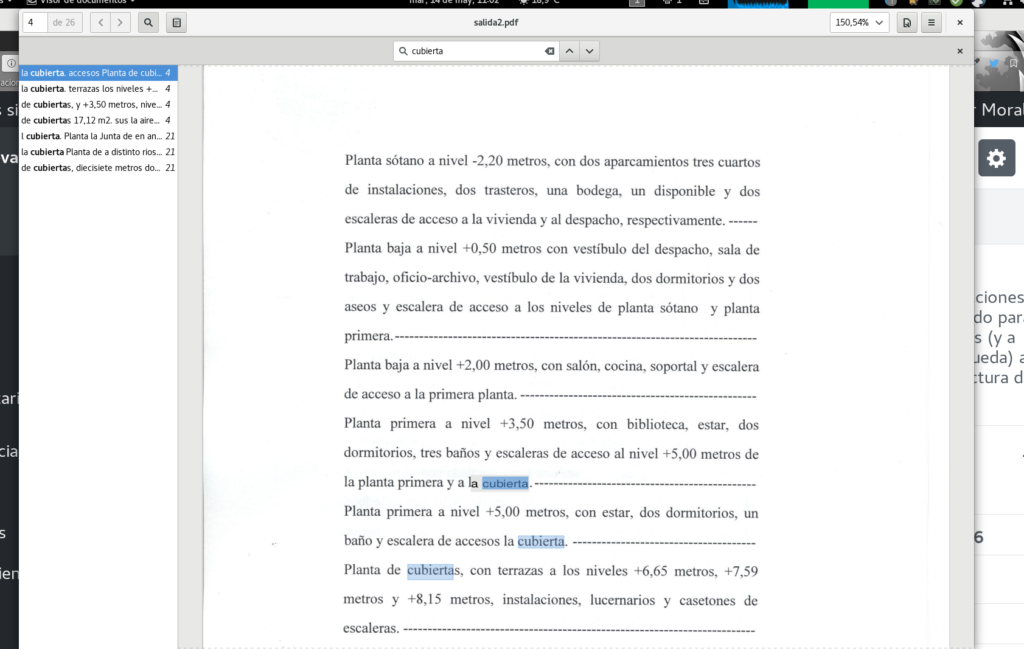
Y por lo que se puede ver en la imagen siguiente es posible encontrar términos en el documento de manera casi idéntica a si su origen fuese un procesador de palabras. Hay que tener en cuenta que las imágenes pueden estar, por ejemplo, ligeramente ladeadas y es por eso por lo que no siempre el texto corresponde a la imagen.
Referencias
- https://superuser.com/questions/427851/batch-resize-and-compress-pdf-files#901510
- https://linuxaria.com/article/tesseract-ocr-convert-images
- https://www.parascript.com/blog/image-quality-for-document-capture-is-more-dpi-always-better/
- https://williamjturkel.net/2013/07/06/doing-ocr-using-command-line-tools-in-linux/